String Matching - Conclusions
Önceki postlarda üç
farklı string matching algoritmasını inceledik ve bu algoritmaları implement
ederek çeşitli durumlarda ortaya çıkan sonuçları gözlemledik. Bu gözlemler
sayesinde algoritmaların etkinliklerini tespit etme şansını elde ettik.
İncelediğimiz algoritmalar farklı etkinliklere ve karmaşıklıklara sahiptir. Aşağıda
elde edilen sonuç bu konu hakkında daha detaylı bilgi vermektedir.
INPUT:
Aranan Pattern: "kullana"
OUTPUT:

Output
verilerinden de anlaşılacağı gibi karşılaştırma sayısı açısından:
Brute-Force > Horspool
> Boyer-Moore
İken
çalışma zamanı açısından ise sonuçlar:
Boyer-Moore > Horspool
> Brute-Force
Şeklindedir. Bu da algoritmaların etkinliklerinin
artmasının her durumda işimize yaramadığını göstermektedir. Basit durumlarda
basit algoritmaların kullanılması karşılaştırma sayısını arttırsa da
karmaşıklığın az olması nedeniyle bu algoritmaların işlemesi daha kısa
sürmektedir. Ayrıca bu algoritmalar karmaşık olmasının yanında daha fazla alan
kullanmaktadırlar:
SBoyer-Moore>SHorspool>SBrute-Force
Fakat bu algoritmalar incelediğimiz text
boyutlarının oldukça büyük olması durumunda ve text’in alfabesinin genişliğinin
fazla olması durumunda işimize yaramaktadır. Böyle bir durumda Horspool ve
Boyer-Moore gibi algoritmalar gereksiz karşılaştırmaların önüne geçerek
kaydırma tablolarını oluşturmak için harcadığı zamanı ileride bu şekilde
kurtarabilmektedir. Bu nedenle bu tür alanlarda daha etkin algoritmalar olan
Horspool ve Boyer-Moore gibi algoritmaların kullanılması daha uygun olmaktadır.
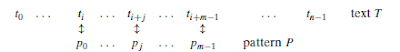
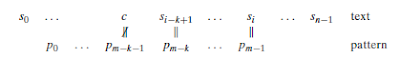

Yorumlar
Yorum Gönder