String Matching - Horspool's Algorithm
Horspool’s Algorithm
Bu konuda brute force string matching algoritmasına alternatif olarak kullanabilecek daha etkin bir algoritma olan Horspool Algoritması açıklanmaktadır.
Brute-Force’a benzer şekilde
pattern’in son harfinden başlanarak soldan sağa doğru pattern ve text’te
karşılıklı denk gelen harfler karşılaştırılır. Eğer pattern’deki tüm
karakterlerin eşleşmesi sağlanırsa substring bulunmuş demektir. Bu durumda
arama durdurulabilir veya başka eşleşme var mı diye aramaya devam edilebilir.
Eşleşme olmazsa pattern’i sağa
kaydırmamız gerekir. Bu durumda herhangi bir eşleşmeyi kaçırma olasılığını
riske atmadan yapabileceğimiz en büyük olası kaydırmayı yapmak isteriz.
Horspool algoritması burada pattern’in son karakterine karşılık gelen (c)
karakterine bakarak kaydırma yapar. Burada dört olasılık söz konusudur. Bu
durumlardan ilerideki sayfalarda bahsedilecek.

BARBER pattern’ini bir text’te
aradığımızı düşünelim.
Pattern’in son elemanı olan R ile
başlayarak sağdan sola doğru hareket ediyoruz ve text ile pattern’de karşılık
gelen karakterleri karşılaştırıyoruz. Eğer pattern’deki karakterlerin tümü
eşleşirse substring bulunmuş demektir.
Eşleşme olmazsa pattern’i sağa
kaydırmamız gerekir. Bu durumda herhangi bir eşleşmeyi kaçırma olasılığını
riske atmadan yapabileceğimiz en büyük olası kaydırmayı yapmak isteriz.
Horspool algoritması burada pattern’in son karakterine karşılık gelen (c)
karakterine bakarak kaydırma yapar.
Burada dört durum söz konusudur.
Durum 1: c harfi pattern’de yoksa örn. örnekteki S harfi. Bu durumda
pattern’i boyutu kadar sağa kaydırabiliriz.(Bu boyuttan küçük bir karşılaştırma
gerçekleştirirsek pattern’i karşılaştırdığımız konumda pattern’de olmayan bir c
harfi ile denk getirmiş oluruz):

Durum 2: Patternde c harfi varsa ve o son karakter değilse örn.
örnekteki B harfi. Kaydırma c harfinin patternde görüldüğü en sağ noktaya denk
gelecek şekilde gerçekleştirilmelidir, bu şekilde patterndeki c harfi ile
text’teki c harfi eşleşmiş olur ve diğer karakteler de eşit mi diye bakılır.

Durum 3: c karakteri patterndeki son karakterse fakat
pattern’in diğer m – 1 karakterinde bu c karakteri yoksa örn. örnekteki R harfi.
Bu durumda, Durum 1’e benzer şekilde pattern boyutu kadar kaydırma yapılır.
Durum 4: c karakteri patterndeki son karakterse ve pattern’in diğer
m – 1 karakterinde bu karakter tekrar ediyorsa örn. örnekteki R harfi. Bu
durumda, Durum 2’ye benzer şekilde patternde c’nin bulunduğu en sağ konuma göre
kaydırma yapılır. Bu sayede text’teki c karakteri ile pattern’deki aynı
karakter hizalanmış olur.

Bu örnek sağdan sola şeklinde
gerçekleştirilen karakter karşılaştırmalarının brute-force algoritmasındaki
gibi her adımda bir kaydırmadan öteye gidebileceğini bize açıkça
göstermektedir. Her turda patterndeki tüm karakterlerin kontrol edilmesi bu
algoritmanın üstünlüğünü ortadan kaldırırdı. Neyse ki girdi geliştirme fikri
tekrar eden karşılaştırmaları gereksiz hale getiriyor. Kaydırma boyutlarını
önceden hesaplayıp bir tabloya atabiliriz. Tablo text’te karşımıza çıkabilecek
tüm olası karakterleri içerecektir; doğal dil text’leri için boşluk, noktalama
işaretleri ve diğer özel karakterler gibi. Tablo, folmül ile bulunan kaydırma
boyutunu gösterecektir.

Örneğin BARBER pattern’i için, E,
B, R ve A karakterleri sırasıyla 1, 2, 3 ve 4 olacaktır. Diğer tüm tablo
girdileri 6’ya eşit olacaktır.
Aşağıda kaydırma tablosunun
hesaplanması için basit bir algoritma verilmiştir. Tablodaki tüm girdileri
pattern’in boyutu olan m değeri başlangıç değeri olarak yüklenir ve pattern
soldan sağa doğru devamındaki aşamayı m – 1 kere tekrar edecek şekilde taranır;
patterndeki j. karakter için (0 <= j <= m – 2) onun tablodaki girdisini m
– 1 – j ile değiştir. Bu da karakterin pattern’in son karakterine olan
uzaklığıdır. Algoritma pattern’i soldan sağa taradığı için son üstüne yazma en
sağdaki karakterde gerçekleşecektir.
ALGORITHM
ShiftTable(P
[0..m
− 1])
//Fills the shift table used by Horspool’s
and Boyer-Moore algorithms
//Input: Pattern P[0..m − 1]
and an alphabet of possible characters
//Output: Table[0..size − 1]
indexed by the alphabet’s characters and
// filled with shift sizes computed by
formula
for
i ←0 to
size − 1 do
Table[i]←m
for
j ←0 to
m − 2 do
Table[P[j ]]←m − 1− j
return
Table
Algoritmayı şu şekilde özetleyebiliriz:
Adım 1 Verilen m boyutlu pattern ve
pattern ve text’te kullanılan alfabe için kaydırma tablosunu yukarda
anlatıldığı gibi oluştur
Adım 2 Pattern’i text’in başına hizala
Adım 3 Bunu eşleşen bir substring bulana kadar ya da text’in sonuna
gelene kadar tekrarla. Tüm m karakteri eşleşene kadar ya da eşleşme bozulana
kadar pattern’deki son karakterden başlayarak, pattern’de ve text’de denk gelen
karakterleri karşılaştır. Eşleşme bozulursa c karakteri için kaydırma
tablosunda denk gelen sayıyı al ve pattern’i bu sayı kadar sağa kaydır.
ALGORITHM
HorspoolMatching(P
[0..m
− 1], T [0..n − 1])
//Input: Pattern P[0..m − 1]
and text T [0..n − 1]
//Output: The index of the left end of the
first matching substring
// or −1
if there are no matches
ShiftTable(P
[0..m
− 1]) //generate Table
of shifts
i ←m − 1
//position
of the pattern’s right end
while
i ≤ n − 1 do
k←0
//number of
matched characters
while
k ≤ m − 1 and
P[m − 1− k]= T [i − k] do
k←k + 1
if
k = m return i − m + 1
else
i ←i + Table[T [i]]
return
−1
ÖRNEK
Horspool
algoritmasının tam uygulamasına örnek vermek gerekirse; İngilizce harflerden ve
boşluktan(alt çizgi ile gösterilen) oluşan bir text’te BARBER kelimesini
arayacak olalım. Öncelikle kaydırma tablosunu önceden belirttiğimiz formül ile
aşağıdaki gibi doldururuz.

Arama işlemi ise aşağıdaki gibi
gerçekleşir.

Horspool algoritmasının worst-key
etkinliği O(nm)’dir. Fakat rastgele textler için bu karmaşıklık Θ(n)’dir ve brute-force sınıfı ile aynı etkinliğe
sahip olsa da Horspool algoritması açıkça görülmektedir ki ona göre daha
hızlıdır. Hatta bu algoritma kendinin daha karmaşık hali olan Boyer-Moore
algoritması kadar etkin sayılır.
C# dili ile uygulanmış hali:
/// <summary>
/// Horspool algoritması için shift tablosunu oluşturur
/// </summary>
/// <param name="text">Kontrol edilecek text</param>
/// <param
name="pattern">Text'te aranacak
kelime</param>
/// <returns>Shift tablosuna uygun verileri atar</returns>
private static void ShiftMyTable(string pattern, string text)
{
bool baskaVar = false;
ShiftTable = new Hashtable(); // Tablo initialize edilir
for (int i = 0; i < text.Length; i++)
{
if (!ShiftTable.ContainsKey(text[i])) //Text'teki değişken tabloya daha önceden eklenmemişse
{
if (!pattern.Contains(text[i].ToString())) //Text'teki harf patternde yoksa
ShiftTable.Add(text[i],
pattern.Length); //O harf için pattern'in
lenght'ini tabloya yaz
else
{//Text'teki
harf patternde varsa
for(int j = pattern.Length - 2; j >= 0; j--)
{
if (pattern[j] == text[i])
{
baskaVar = true;
ShiftTable.Add(text[i],
pattern.Length - j - 1); //Sondan başlayarak o harfin
patterndeki konumuna göre tabloya değeri atar
break;
}
}
if (baskaVar == false)
ShiftTable.Add(text[i],
pattern.Length);
else
baskaVar = false;}}}}
Yukarıdaki algoritma Horspool
Algoritması için kullanılan kaydırma tablosunu oluşturan algoritmanın C#’ta
implement edilmiş halidir. Bu method parametre olarak pattern ve text
değişkenlerini almaktadır.
for (int i = 0; i < text.Length; i++)
Text’teki tüm karakterler için
kaydırma değeri belirleniyor.
if
(!ShiftTable.ContainsKey(text[i]))
Text’teki karakter daha önceden tabloya eklenmişse tekrar
eklenmesi gerekmemesi için kullanılan koşul.
if
(!pattern.Contains(text[i].ToString()))
Eğer text’teki karakter patternde yoksa o karakter için tabloda m
değeri yani pattern’in boyutu atanmaktadır. Karakter patternde varsa karakterin
konumunu sağdan başlayarak hesaplıyoruz ve bulduğumuz değer karakterin kaydırma
tablosundaki değer oluyor.
/// <summary>
/// Horspool algoritmasını kullanarak verilen text'te pattern
eşleşmesi olup olmadığını bulur ve eşleşme varsa eşleşmenin konumunu döndürür
/// </summary>
/// <param
name="text">Kontrol edilecek text</param>
/// <param
name="pattern">Text'te aranacak
kelime</param>
/// <returns>Pattern eşleşmesinin konumunu döndürür</returns>
private static int HorspoolMatching(string pattern, string text)
{
ShiftMyTable(pattern, text); //Shift tablosunun hesaplanması için method çağrılıyor
int i = pattern.Length - 1;
while (i <= text.Length - 1) //index
lenght'ten kısa ise döngüye giriliyor
{
int k = 0;
while (k <= pattern.Length - 1 &&
pattern[pattern.Length - 1 - k] == text[i - k]) //Key
comparison; karşılaştırılan harfler eşitse girilir
{
k++;
}
if (k == pattern.Length) //Pattern
bulunduysa
{
return i - pattern.Length + 1; //Eşleşmenin
konumu döndürülüyor
}
else
{
i = i + Convert.ToInt32(ShiftTable[text[i]].ToString());
// Eşleşme olmadıysa shift tablosuna göre
index shift ediliyor
}}
return -1; //pattern eşleşmesi yoksa -1
döndürülüyor
}
Algoritma parametre olarak pattern ve text’i alıyor. Daha sonra
kaydırma tablosu oluşturuluyor. Eşleşme sağlanırsa k değişkeninin değeri
artıyor. k değişkeni m değerine ulaşırsa bu pattern’i textte bulduğumuz
anlamına geliyor. Farkı bir durum olursa pattern kaydırma tablosuna göre sağa
kaydırılıyor ve karşılaştırmaya devam ediliyor.
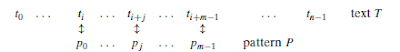
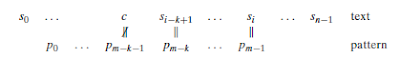
merhaba, Bir sorum olacaktı.. Patterni kendimiz vermesek, yani Örnekte verdiğiniz gibi BARBER kelimesini bilmesek algoritmanın bunu bulmasını beklediğimizde uygulanacak algoritma hangisidir?
YanıtlaSilteşekkürler.
YanıtlaSil